電腦系統的四個組成要素:硬體設備、作業系統、應用程式、使用者,作業系統基於硬體而乘載應用程式,作業系統負責控制並協調分配(硬體)資源給各個應用
系統觀點
綜上所述

一、Process 是一個實體。每一個 process 都有它自己的 address space,一般情况下,包括

二、Process 是一個「執行中的 Program」,是獲取 CPU / Memory 資源的單位
Process 由 Program、Data 和 Process Control 三部分组成。多個不同的 Process 可以包含相同的 Program,Program 可以就理解為是一段程式代碼 code;一個 Program 在不同的 context 裡就構成不同的 Process,能得到不同的結果;但是執行過程中,Program 不能發生改變。



Linux 的 PCB 實作是定義了 C 的 task_struct。所有活動中的 process 的 PCB 構成一個雙向的 link list。Kernel 維持一個 pointer "current" 指向正在執行中的 process 的 PCB。


Multithread 多執行緒 benefits

signal 原用來通知 process 某個 event 發生。在導入 thread 概念後,就面臨 signal 要送往 process 中哪一個 thread 的問題。UNIX 允許 thread 在創立時指定其要接收/阻擋哪些型態的 signal。而 signal 只需被處理一次,所以通常 signal 只傳送到第一個接受他的 thread。標準 UNIX 的發送 signal function 為 kill(pid, signal),POSIX Pthread 提供 pthread_kill(tid, signal)。
Thread 為後導入的概念,Linux 沒有明確創造 thread 的 system call,而是利用 clone()。因為 Linux 系統在實際控制時,是採用 task 的概念而非 process 或 thread。clone 可指定與父行程有多少共用,若指定為 CLONE_FS | CLONE_VM | CLONE_SIGHAND | CLONE_FILES,代表共用 file system info、memory space、signal handler、opened files,則即相當於創造一個 thread。若都沒有共用,基本上與 fork() 效果一樣。
在這樣的實作之下,clone() 一樣造成一個新的 PCB 產生,只是其中特定欄位為指向父 process 的 PCB 的特定欄位的指標,還記得 PCB 在 Linux 中的實作 struct 稱為 task_struct,由此可見 Linux 的工作管理單位為 task,並沒有直接的 procss/thread 分別意識,都僅是透過 PCB task_struct 的內容來處置 。
Semaphore 是一件可以容納 N 人的房間,如果人不滿就可以進去,如果人滿了,就要等待有人出來。對於 N=1 的情況,稱為 binary semaphore。一般的用法是,用於限制對於某一資源的同時訪問。
在有的系統中 Binary semaphore 與 Mutex 是沒有差異的。在有的系統上,主要的差異是 mutex 一定要由獲得鎖的 process 來釋放,而 semaphore 可以由其它 process 釋放,這時的 semaphore 實際就是個 atomic 的變量,大家可以加或減,因此 semaphore 可以用於進程間同步。
Semaphore 的同步功能是所有系統都支持的,而 Mutex 能否由其他 process 釋放則未定,因此建議 mutex 只用於保護 critical section。而 semaphore 則用於保護某變量,或者同步。

CPU 所產生的是 logical address,RAM 在其 memory-address register 看到的是 physical address,如果這兩者在實務上不相等,那就是所謂 virtual memory 的效果,在兩者之間的 mapping 要透過稱為 memory-management unit (MMU) 的硬體裝置支援來完成。
Physical memory 被分割成 frame 的固定大小區段,logical memory 被分割成 page,disk 中作為 swap 用途的區域也被以相同大小分割。當一個 process 要被執行時,他的 page 就被載入到可用的 frame 中。

一些作業系統對於 IPC 的 shared memory 也是透過共用分頁來實作的。
編譯階段會在該段做個記號,該記號其實就是一小段 code 指示該如何去找到該 program,當執行到該記號時,首先則會檢查該 program 文本是否已經在 memory 中,若沒有則將其找到並載入,並執行,與此同時 link 也完成,之後不用在 link 一次。
更進一步來說,可以在平台上維持不同版本的 library,user program 可指定其要 link 的版本,所以又稱為 shared libraries。
Dynamic link 需要 OS 的支持,因為要做到某一 shared library 不被重複的載入 memory,也就是後來者需要去 access 先來者的 address space 中載入的 shared library 的部分,這想必需要 OS 介入才能進行。而 dynamic load 則不需要 OS 的介入,純粹是在 coding 時的一種技巧選擇,以及須將 library 編譯成 relocatable code。Dynamic link 明確意涵 share 的方式來達到 save memory 的效果,藉由 OS 的幫助;dynamic load 是透過需要時才載入,不需要時釋放來達到 save memory 的效果,須由程式設計師明確使用。
 當欲使用到的 page 不在 memory 中時,這是由支援 page 的 HW 發現的 (MMU),他注意到該 page 的 invalid bit 被設置,而發出一個 interrupt page fault。處理 page fault 流程:
當欲使用到的 page 不在 memory 中時,這是由支援 page 的 HW 發現的 (MMU),他注意到該 page 的 invalid bit 被設置,而發出一個 interrupt page fault。處理 page fault 流程:
Process 在開始時會做 demand paging,而 lazy swap 所造成的成本是與 page fault 發生的機率相關的。如果 page fault 越常發生,平均 demand paging 時間就會越長。
Linux 另外提供了 vfork() 方法,就是應用於預期子行程和父行程完全共用分頁的狀況。實際運作上相當於, vfork() 之後父行程就暫停,子行程使用了父行程的 address space,子行程接束之後,父行程所復得的 address space 都是子行程操作過的狀態。

系統觀點
- 作業系統是電腦上的資源分配者,負責管理並有效且公平地分配資源,如:cpu 時間、記憶體空間、檔案儲存空間、I/O 裝置
- 作業系統是一個控制程式,在開機後持續執行,以管理軟、硬體資源
- 其核心 (kernel) 是作業系統運作的基本元件
- 系統程式是除了核心以外,幫助系統運作的程式,而其他解決使用者的問題皆稱為應用程式
Startup
- 靴帶式程式 (bootstrap program) 存於
- 唯讀記憶體 (ROM) 或
- 可消除式唯讀記憶體(EEPROM)
- 通常稱為韌體 firmware
- 將作業系統核心 (kernel) 載入記憶體
- 執行第一個行程- init
- 協調事件之中斷 (interrupt)
System Boot
- 藉由載入核心來開啟一部電腦的步驟就是 booting 系統
- 在大部份電腦系統之中,有一小段程式碼叫做靴帶式程式 bootstrap program 或叫做 bootstrap loader
- 有些電腦系統如 PC 把這個步驟分成兩個階段,先有一個非常簡單的 bootstrap loader 從 (EEP)ROM 載入一個更複雜的 loader,然後再由後者將 OS kernel 載入
- loader 通常在 ROM 中因為不常需要改變,基本上與 HW 綁定;OS 則在 disk 中可以接受改變,不與 HW 綁定
從開機到 main() 的執行分三步完成(當執行到 main() 代表已完全進入 OS 接管):
第一步,啟動 BIOS,准備 實模式 下的 中斷向量表 和 中斷服務程序
第二步,從啟動盤加載 OS program 到 RAM,加載 OS program 的工作就是利用第一步中所准備的中斷服務程序實現的
第三步,為執行 32-bit 的 main() 函數做過度工作
- 啟動 BIOS (loader),准備 實模式 下的 中斷向量表 和 中斷服務程序
- 上電的一瞬間,計算機的 RAM 中什麼程序也沒有
- Disk 中雖然有 OS 程序,但 CPU 的邏輯電路設計為只能運行 RAM 中的 program,它沒有能力直接從 disk 運行 OS,必須將 disk 中的 OS 加載到 RAM 中
- BIOS 如何被啟動 (BIOS 就是在 PC 上的 loader 角色)
- CPU 硬件邏輯設計為加電瞬間強行將 CS 的值置為 0xF000,IP 的值置為 0xFFF0,這樣 CS:IP 就指向 0xFFFF0 這個地址位置
- CS 和 IP 是兩個 register
- CS = Code Segment,是指一個程式是從哪個位址開始,例如從000A,CS 裡面就會記載 000A
- CS 通常會搭配 IP (Instruction Pointer) 使用,程式目前跑到的位置,就由 (CS)0 + IP 決定
- 如果計算機加電之後這個位置沒有可執行代碼,那計算機就此死機;反之,如果這個位置有可執行代碼,計算機將從這裡的代碼開始,沿著後續程序一直執行下去
- BIOS 程序的入口地址就是 0xFFFF0,也就是說,BIOS 程序的第一條指令就設計在這個位置
- BIOS 在 RAM 中加載 中斷向量表 和 中斷服務程序
- BIOS 程序在 RAM 最開始的位置 0x00000 用 1KB 的內存空間 0x00000-0x003FF 構建 中斷向量表
- 中斷向量表:表中記錄所有中斷號對應的中斷服務程序的 Memory Address
- 並在緊挨著它的位置用 256 Byte 的 Memory 構建 BIOS 數據區 (0x00400-0x004FF)
- 在大約 56KB 以後的位置 (0x0E2CE) 加載了 8KB 左右的中斷向量表相應的若干中斷服務程序
- 中斷服務程序 ISR:通過中斷向量表中的索引對中斷進行響應服務,是一些具有特定功能的程序。由中斷所指定執行的程式就叫做中斷服務程式 Interrupt Service Routine
- 可以想像目前加載的 ISR 應只是部分的,當前階段主要目的只是支援後續將 kernel 成功載入,而之後會由 kernel 接管,driver 可藉由 kernel 註冊中斷
- 中斷向量表中有 256 個中斷向量,也就是有 256 個中斷號;每個中斷號所對應的中斷向量各占 4 個字節,其中 2 個字節是 CS,兩個字節是 IP,每個中斷向量都指向一個具體的中斷服務程序
- 稍後就會利用這些中斷服務程序把 kernel 從 disk 加載至 RAM
- 加載 OS kernel 程序並為保護模式做准備
- 現在開始就要執行真正的 boot 操作了,即把 disk 中的 OS program 加載至 RAM
- 加載第一部分代碼- 引導程序 bootsect
- 計算機硬件體系結構的設計與 BIOS 聯手操作,會使 CPU 接收到一個 int 0x19 中斷
- CPU 接收到這個中斷後,會立即在中斷向量表中找到 int 0x19 中斷向量
- 中斷向量把 CPU 指向 0x0E6F2,這個位置就是 int 0x19 想對應的中斷服務程序的入口地址,即「啟動加載服務程序」的入口地址
- 這個中斷服務程序的工作內容就是把 disk 的第一個扇區的 program 加載到 RAM 中的指定位置 0x07C00
- 這個中斷服務程序的功能是 BIOS 事先設計好的,代碼是固定的,與什麼OS 無關,無論該 OS kernel 是如何設計,這段 BIOS program 所要做到就是找到 disk 並加載第一扇區。其餘的它什麼都不知道也不必知道
- 而現在 RAM 0x07C00 中的 bootsect 工作就是陸續把 disk 中的 OS 程序載入內存,也就是說從此以後就是 OS 主管的部分了
- 上電後硬件設計使 CS:IP 初始值指向 BIOS 第一行指令所在位置
- BIOS 因此能建立中斷向量表
- BIOS 搭配硬件設計發出 0x19 中斷
- CPU 收到中斷後查詢中斷向量表找到「啟動加載服務程序」並執行之
- 啟動加載服務程序會將 disk 中第一個扇區的 program 加載到 RAM 中的指定位置,此 program 即為 bootsect 引導程序
- bootsect 的工作就是將 OS 的其他程序載入,也就是 bootsect 和 bootsect 以後即為 OS 設計的部分,以前為 BIOS 和硬件設計的部分
中斷 Interrupt
- 用來通知「事件」發生
- 硬體中斷:硬體或說 device 可在任何時間藉由發給 CPU 一個信號 signal 而觸發 interrupt
- 軟體中斷:program 可藉由 system call 觸發中斷
- 中斷的類別是有限數量且預先定義的,藉由中斷向量表讓 CPU 在收到中斷要求後,查詢對應該型態的中斷的中斷處理常式 (Interrupt Service Routine ISR) 並交付執行
Interrupt 的處理流程
- 暫停目前 process 之執行
- 保存此 process 當時執行狀況。
- OS 根據 Interrupt ID 查尋 Interrupt vector
- 取得 ISR(Interrupt Service Routine)的起始位址
- ISR 執行
- ISR 執行完成,回到原先中斷前的執行
System Call
運行在 User Speace 的程序向 Kernel 請求需要更高許可權運行的服務。System Call 提供了用戶程序與作業系統之間的介面。大多數系統互動式操作需求在 kernel mode 執行,如device IO 操作或者 process 間通信。也就是說一個 process 會有處於 kernel mode 而用擁有 high privilege 的時候,有會有處於 user mode 的時候。而 user mode 到 kernel mode 這轉換是透過 system call,在 system call 這個 request 被處理的時候,也就意味著 OS 取代 user program 的而取得該 process 的控制權。系統呼叫參數傳遞方法
System Call 支援參數傳遞,傳遞方法有:
- 暫存器參數 By Register
- 使用者程式 (User Program) 將參數寫入暫存器 (Register),再由作業系統將參數讀取使用
- 暫存器價值昂貴且反應迅速,故其優點是傳遞速度迅速;缺點是價格高
- 一個暫存器只可傳遞一個參數,若參數之數量多於暫存器之數量,則將無法執行
- 地址參數 By Address
- 如果參數量大,可將參數放在 memory,並將 memory 區段的位址透過 register 傳遞給予作業系統,作業系統再依址讀取參數使用
- 優點是可執行大量參數的傳遞;缺點是速度較慢
- Linux 採用此方法
- 堆疊參數 By Stack
- 使用者程式將參數 Push Stack,作業系統再由堆疊將参數 Pop 使用
- 優點是執行大量參數的傳遞,且執行步驟井然有序;缺點是速度較慢
Types of System Calls
系統呼叫可分為:行程控制 (Process Control)、檔案操作 (File Manipulation)、裝置操作 (Device Manipulation)、資料維護 (Information Maintenance) 、連線訊 (Communication)Process Control
- Process 的啟動與終止
- 呼叫作業系統執行載入 Load,將程式指令從主記憶體抓取至 CPU 執行 Execute
- 呼叫作業系統 Create Process;執行完畢後,呼叫作業系統執行 Terminate Process,e.g. Linux 的 fork()
- 在正常情況下,呼叫作業系統 End Program;在有錯誤的情況下,呼叫作業系統 Abort Program,並印出錯誤信息,e.g. Linux 的 exit()
- Allocate and Free Memory
- Process Attributes
- 在執行過程中,為了配合其他 Process 的需要,往往要了解其他 Process 的屬性,此時呼叫作業系統 Get Process Attributes;亦或 Set Process Attributes 以供其他行程觀察使用
- Wait
- 在執行過程中,有許多情況需要 Process 作等待,等待進入 CPU、等待滑鼠事件、等待鍵盤事件等等,呼叫作業系統執行行程等待,e.g. Linux 的 wait()
File Management
一組 data 或一個 program 儲存於連續的 Storage 內,以一個名稱代表之,是謂 File。在記憶體建立檔案、存取檔案等等作為,均須作系統呼叫由作業系統導引執行,其中項目有:- Create / Delete File
建立或刪除一個檔案,均會改變記憶體的使用情況,必須呼叫作業系統導引執行 - Read / Write
存取檔案資料必經之過程為... 為了安全,均須呼叫作業系統導引執行 - 開啟檔案 Open File,e.g. Linux 的 open()
- 存取檔案 Read / Write,e.g. Linux 的 read(), write()
- 關閉檔案 Close File,e.g. Linux 的 close()
- File Attributes
- 為了配合存取檔案的需要,往往需要了解其他檔案的屬性,此時呼叫作業系統 Get File Attributes;亦或呼叫作業系統設定本身檔案的屬性 Set File Attributes,以供其他檔案讀取使用
Devices Management
電腦系統之各項硬體資源與週邊設備均歸類為裝置 Device- Request / Release Device
- 在電腦系統中,Device 即是一種資源,當 Process Request 或 Release 某項裝置時,須呼叫作業系統導引執行,e.g. Linux 的 ioctl()
- Read / Write
- 存取裝置資料是 I/O 行為,為了安全須呼叫作業系統導引執行,e.g. Linux 的 read(), write()
- 比如 user program 中的 printf(),其在 stdio Library 中的實作即會使用到 system call 的 write(),而執行 printf() 則會經歷由 user mode 轉到 kernel mode 再回到 user mode
- Device Attributes
- 為了配合裝置執行 I/O 的需要,往往需要了解裝置的屬性,此時呼叫作業系統 Get Device Attributes;亦或呼叫作業系統 Set Device Attributes 以供讀取使用
- 邏輯連接 Logically Attach / Detach
- 於程式 Program 內設定一個名稱,比擬為某境外裝置,並作存取資料的連通,如此行為是謂「邏輯連接」,且需呼叫作業系統導引執行
Information Maintenance
隨著時間的改變,將資料更新是謂 Information Maintenance。如果是系統資料的更新,為了安全,須作系統呼叫執行- Set Time or Date:e.g. Linux 的 time(), date(), alarm(), sleep()
- Get / Set System Data:e.g. trace, dump
- Get / Set Process、File、or Device Attributes:e.g. Linux 的 getpid()
Communication
比如 process 間的通訊或分散式系統中系統間的通訊。分散式系統是將散置各處的電腦以連線連通,執行訊息傳遞等 I/O 存取行為,故須作系統呼叫執行:- Create / Delete Communication Connection
- IPC 如 Linux 中的 pipe(), shmget(), mmap()
- 分散式系統中,實體連線的連接屬於網路實體層,如要改變現狀,需呼叫作業系統導引執行
- Send / Receive Messages
- 網路資料的輸入輸出牽涉甚多,除了 I/O 機制外,還有網路機制等問題,絕非程式本身可單獨執行者,為了安全,為了克服重重機制,需呼叫作業系統導引執行
- Transfer Status Information
- 為了配合不同的環境條件,系統須對某些區塊設定狀態旗標 (Status Flag),媒合執行行程,如要轉換這些狀態資訊,需呼叫作業系統導引執行
- Attach / Detach Remote Devices
- 當使用網路遠端其他電腦或裝置時,系統應有相對之使用訊息,以供資源分配的依據,如果使用情況改變,需呼叫作業系統導引執行改變對應之使用訊息
Protection
- set / get permission
- allow / deny user
- 如 Linux 中的 chmod(), umask(), chown()
系統程式 System Program (系統工具)
OS 一方面也可以說成是 「kernel + 系統程式」,電腦架構由下到上可以看成依序為:hardware => OS => system program => application。
很多 system program 其實僅簡單是封裝 system call 的給 user 的 API,所以上述的 system call 類別也都可以看到對應的 system program 的實例。另外如編譯器、組譯器、直譯器等也是系統程式的一種。
Unix 系統結構

Process
行程 Precess 的概念主要有兩點:一、Process 是一個實體。每一個 process 都有它自己的 address space,一般情况下,包括
- 文本區域 text region:存放著要 CPU 執行的 code
- data region:global variable
- heap region:Process 執行期間使用的動態分配 (allocate) 的 memory
- stack region:存活動過程調用的指令和 local variable;存暫用資料如副程式的參數、返回位址,及暫時性變數

Process 由 Program、Data 和 Process Control 三部分组成。多個不同的 Process 可以包含相同的 Program,Program 可以就理解為是一段程式代碼 code;一個 Program 在不同的 context 裡就構成不同的 Process,能得到不同的結果;但是執行過程中,Program 不能發生改變。
State
Process 的基本狀態有三種:就緒 Ready、執行 Running、等待 Waiting (阻塞)- 就緒 Ready:當 Process 已分配到除 CPU 以外的所有必要資源後,只要在獲得 CPU,便可立即執行,Process 這時的狀態稱為就緒狀態。處於該狀態的 Process 構 Ready Queue
- 執行 Running:Process 正在處理器上運行的狀態,該 Process 已獲得必要的資源,也獲得了 CPU,意謂 user program 正在 CPU 上運行
- 等待(阻塞) Wait:正在執行的 Process 由於發生某事件而暫時無法繼續執行時,放棄 CPU 而處於暫停狀態;即 Process 的執行受到阻塞,成為阻塞狀態,也成為等待狀態

行程控制表 Process Control Block (PCB)
每一個 Process 在 OS 之中都對應著一個行程控制表 Process control block PCB,也可稱為任務控制表 Task control block。裡面記錄
- 行程狀態 Process state:running、waiting
- 程式計數器 Program counter:指出行程接著要執行的指令位址
- CPU registers 內容
- CPU scheduling information:行程的 priorities、scheduling queue 指標以及其它的排班參數
- Memory-management information:分配給行程的記憶體
- Accounting information:CPU 和實際時間的使用數量、時限、帳號工作或行程號碼
- I/O status information:配置給行程的輸入/輸出裝置,開啟檔案的串列
(上述只討論 single thread 的狀況,若為 multi-thread 則 PCB 中需加入每個 thread 的資訊)
在 PCB 記錄的幫助之下,CPU 便可在多個 Process 間切換而達到多工的效果:

Linux 的 PCB 實作是定義了 C 的 task_struct。所有活動中的 process 的 PCB 構成一個雙向的 link list。Kernel 維持一個 pointer "current" 指向正在執行中的 process 的 PCB。
Process 的創建
一旦 OS 發現了要求創建新 Process 的事件後,便調用 creat() 按下述步驟創建一個新 Process- 申請空白 PCB:為新行程申請獲得唯一的數字標識符,並從 PCB 集合中索取一個空白PCB
- 為新 Process 分配資源:為新 process 分配必要的內存空間。顯然此時 OS 必須知道新 process 所需要的 memory 大小
- 初始化 PCB:包括
- 初始化標識信息,將系統分配的標識符 pid 和 parent process pid 填入新的 PCB 中
- 初始化 CPU 狀態 information,使程序計數器 program counter (PC) 指向 program 的入口 address,使 stack pointer 指向 top of stack
- 初始化 CPU 控制 information,將 process 的狀態設置為 ready;對於優先級通常是設置為最低優先級,除非用戶提出高優先級要求
- 將新 process 插入 ready queue (如果 ready queue 能夠接納新行程)
Process 终止
引起 Process 终止的事件
- 正常結束
- 在任何計算機系統中,都應該有一個表示 process 已經運行完成的指示
- 異常結束
- 在 process 運行期間,由於出現某些錯誤和故障而迫使行程終止
- 這類異常事件很多,常見的有:越界錯誤,保護錯,非法指令,特權指令錯,運行超時,等待超時,算術運算錯,I/O故障
- 外界干預
- 外界干預並非指在本行程運行中出現了異常事件,而是指行程應外界的請求而終止運行
- 這些干預有:操作員或操作系統干預,父行程請求,父行程終止
Process 的终止過程
如果系統發生了上述要求終止 Process 的某事件後,OS 按下述過程去終止指定的 Process- 根據被終止 process 的標識符,從 PCB 集合中檢索出該行程的 PCB,從中讀出該 process 狀態
- 若被終止 process 正處於 running 狀態,應立即終止該 process 的執行,並置調度標誌為真。用於指示該行程被終止後應重新進行調度
- 若該 process 還有子孫 process,還應將其所有子孫 process 予以終止,以防他們成為不可控的 process (cascading termination)
- UNIX 的做法是將子 process 的 parent 設為 init process
- 將被終止的 process 所擁有的全部資源,或者歸還給其父 Process,或者歸還給系統
- 將被終止 process (它的PCB) 從所在 queue (或 list) 中移出,等待其它 process 來蒐集信息
Process 的等待 (阻塞) 喚醒
引起行程等待 (阻塞) 和喚醒的事件
- 請求系統服務
- 當正在執行的 process 請求 OS 提供服務時,由於某種原因,OS 並不立即滿足該 process 的要求時,該 process 只能轉變為阻塞狀態來等待,一旦要求得到滿足後,process 被喚醒
- 啟動某種操作
- 當 process 啟動某種操作後,如果該 process 必須在該操作完成之後才能繼續執行,則必須先使該 process 阻塞,以等待該操作完成,該操作完成後,將該 process 喚醒
- 新數據尚未到達
- 對於相互合作的 process,如果其中一個 process 需要先獲得另一 process 提供的數據才能運行以對數據進行處理,則要是其所需數據尚未到達,該 process 只有等待阻塞,等到數據到達後,該 process 被喚醒
- 無新工作可做
- 系統往往設置一些具有某特定功能的 System Process,每當這種 process 完成任務後,便把自己阻塞起來以等待新任務到來,新任務到達後,該 system process 被喚醒
Process 阻塞過程
- 正在 running 的 process,當發現上述某事件後,由於無法繼續執行,於是 process 便通過調用 block() 把自己阻塞 (Process 的阻塞是 process 自身的一種主動行為)
- 進入 block 過程後,由於此時該 process 還處於 running 狀態,所以應先立即停止執行,把 PCB 中的現行狀態由 running 改為 waiting,並將 PCB 插入阻塞隊列。如果系統中設置了因不同事件而阻塞的多個阻塞隊列,則應將本行程插入到具有相同事件的阻塞(等待)隊列,比如正在等待某 I/O device (e.g. disk) 的 process 所形成的 queue 極為 device queue,每個 device 都有個別的 device queue。
- 最後轉調度程序進行重新調度,將 CPU 分配給另一 ready process 並進行切換,亦即保留被阻塞 process 的 CPU 狀態在 PCB 中,再按新 process 的 PCB 中的 CPU 狀態設置 CPU 環境,這即稱為 Context Switch

Process 喚醒過程
- 當被阻塞的 process 所期待的事件出現時,如 I/O 完成或者其所期待的數據已經到達,則由有關 process (比如用完並釋放了該 I/O 設備的 process) 調用 wakeup() 將等待該事件的 process 喚醒
- wakeup() 的過程是:首先把被阻塞的 process 從等待該事件的阻塞隊列中移出,將其 PCB 中的現行狀態由 waiting 改為 ready,然後再將該 PCB 插入到就緒隊列中
Process Scheduler
Scheduling Queues
- Process 進入系統時,是放在 Job Queue 中,此 queue 是由系統中所有的 process 所組成
- 位於 memory 中且 ready 等待執行的 process 是保存在一個 Ready Queue 的 linked list。Ready queue 前端保存著指向這個 list 的第一個和最後一個 PCB 的指標
- Process 可發出 I/0 要求,然後置於一個 I/0 Queue 中
- Process 可產生出一個新的子 Process 並等待後者的結束
- Process 可強行地移離 CPU,如用中斷的結果一樣,然後放回 Ready queue 中
更進一步,一般來說 process 數量都超過電腦一次能負荷的數量,所以 process 會先以 spooled 方式送到 disk 中 (或 secondary storage) 等待。long-term scheduler (或稱 job scheduler) 從 pool 中選出放入 memory 中。short-term scheduler 從 memory 中選出放入 ready queue。
long-term scheduler 的重要工作是選擇適當比例的 I/O-bond 和 CPU-bond process 進入 memory,以達到 CPU 的最大利用率,也就是不應後續導致 ready queue 為空的狀況。
許多分時系統是沒有 long-term scheduler 的,比如 UNIX 和 Windows。在只使用 short-term scheduler 的狀況下,若發生 memory 若不足以支撐新增更多的 process,那不夠了就是不夠了,user 須等到有 process 結束釋出資源。然而,為了改善此問題,新增的角色是 mid-term scheduler,或稱 swap。
long-term scheduler 的重要工作是選擇適當比例的 I/O-bond 和 CPU-bond process 進入 memory,以達到 CPU 的最大利用率,也就是不應後續導致 ready queue 為空的狀況。
許多分時系統是沒有 long-term scheduler 的,比如 UNIX 和 Windows。在只使用 short-term scheduler 的狀況下,若發生 memory 若不足以支撐新增更多的 process,那不夠了就是不夠了,user 須等到有 process 結束釋出資源。然而,為了改善此問題,新增的角色是 mid-term scheduler,或稱 swap。
排班演算法
- FCFS
- SJF
- priority queue
- RR
- multilayer queue
- multilevel feedback queue
Interprocess Communication

Shared-Memory Systems
POSIX (Linux) 中的 shmget()
Message-Passing Systems
- 概念不但適用於 process 間,system/host 間也一樣適用,比如 UNIX socket、TCP/UDP socket、RPC
- pipe
- pipe() 是最基本的 process 間通訊
- UNIX 把 pipe 當成是一個特別的檔案型態,因此可以對其做 read() / write(),fd[0] 是讀取端,fd[1] 是寫入端
- 一般來說 pipe 只用於父行程和子行程之間的通訊,子行程因繼承父行程的 fd 變數因此也可以 access pipe
- 基本上 pipe 為單向,所以若要雙向溝通,須建立兩個 pipe
- named pipe
- UNIX 中實作稱為 FIFO,mkfifio(),如同創造一個典型的 file
- 會持續存在直到明確將其從 file system 中刪除 (一般 pipe 在 process 消失時就消失了)
- UNIX fifo 只是半雙工,若要雙向通訊一樣要兩個 fifo
Thread
若導入 thread 的概念,process 應被理解為是擁有資源的實體,本身不會被稱為是用來「執行」的;而 thread 即是被用來在 CPU 當中「執行」的單位。Multithread 多執行緒 benefits
- Responsiveness:響應度高,一個 multi-thread 的應用在執行中,即使其中的某個 thread 堵塞,其他的 thread 還可繼續執行,從而提高響應速度
- Resource Sharing:同一 process 的多個 thread 共享該 process 的 memory 等資源
- Economy:創建和切換 thread 的開銷要低於 process
- Scalability:行程可以採用 multi-core 結構

用戶執行緒 (User Threads) 和 內核執行緒 (Kernel Threads)
- 分別在 thread 機制是在 application 層提供還是由 OS kernel 提供。
- 多對一模式指的是多個 application layer user thread 對應到單一個 kernel thread,此時若其中一個 user thread 呼叫暫停,對應的 kernel thread 也因此暫停,進而導致所有其他 user thread 也須暫停
- 一對一模式指的是每個 user thread 都對應到一個 kernel thread,這種方法勢必需要限制最大支援的 thread 數量因為 kernel 資源是很有限的,Linux 和 Windows 皆採用此模式
- Java 一樣在 JVM 抽象化了 thread,所以取決於 JVM 是在什麼平台上而決定了他實際上的 thread 實作方法
Linux thread
Unix 中的 fork() 方法在導入 thread 概念後可支援- 產生一子 process,並複製所有的 thread
- 產生一子 process,只複製當前的 thread
signal 原用來通知 process 某個 event 發生。在導入 thread 概念後,就面臨 signal 要送往 process 中哪一個 thread 的問題。UNIX 允許 thread 在創立時指定其要接收/阻擋哪些型態的 signal。而 signal 只需被處理一次,所以通常 signal 只傳送到第一個接受他的 thread。標準 UNIX 的發送 signal function 為 kill(pid, signal),POSIX Pthread 提供 pthread_kill(tid, signal)。
Thread 為後導入的概念,Linux 沒有明確創造 thread 的 system call,而是利用 clone()。因為 Linux 系統在實際控制時,是採用 task 的概念而非 process 或 thread。clone 可指定與父行程有多少共用,若指定為 CLONE_FS | CLONE_VM | CLONE_SIGHAND | CLONE_FILES,代表共用 file system info、memory space、signal handler、opened files,則即相當於創造一個 thread。若都沒有共用,基本上與 fork() 效果一樣。
在這樣的實作之下,clone() 一樣造成一個新的 PCB 產生,只是其中特定欄位為指向父 process 的 PCB 的特定欄位的指標,還記得 PCB 在 Linux 中的實作 struct 稱為 task_struct,由此可見 Linux 的工作管理單位為 task,並沒有直接的 procss/thread 分別意識,都僅是透過 PCB task_struct 的內容來處置 。
Thread 排班
TBCSynchronization
比如兩個工作同時想去更改記憶體中的某個變數,context switch 的過程並不會更新記憶體的資料,造成最後用舊的資料計算,產生錯誤的結果。更明確的說,已經被載入到 register 中的變數,因為 context switch 會記錄 register 值,所以若發生 context switch 的前後兩個 process 對同一變數做操作,則互相是不知道對方對變數做了什麼操作的,這就稱為 race condition。
Critical Section
須滿足的三個條件:
- Mutual Exclusion 互斥:當有一個 process 佔住 critical-section 時,其他 process 不能進入 critical section,不會有兩個 process 同時間在 critical-section 中工作
- Progress:當沒有 process 要在 critical-section 中執行時,不能阻擋其他想要進入 critical section 工作的 process 進入 critical-section,要選擇其中一個候選 process 進入 critical-section,不能空在那邊。(延遲:postponed)
- Bounded Waiting:等待 critical-section 的時間,不能是無窮大的時間,是有個界線。也就是說,不能佔住了critical-section 就不出來了
Lock
Mutex 是一把鑰匙,一個人拿了就可進入一個房間,出來的時候把鑰匙交給隊列的第一個。一般的用法是用於串行化對 critical section 代碼的訪問,保證這段代碼不會被並行的運行。Semaphore 是一件可以容納 N 人的房間,如果人不滿就可以進去,如果人滿了,就要等待有人出來。對於 N=1 的情況,稱為 binary semaphore。一般的用法是,用於限制對於某一資源的同時訪問。
在有的系統中 Binary semaphore 與 Mutex 是沒有差異的。在有的系統上,主要的差異是 mutex 一定要由獲得鎖的 process 來釋放,而 semaphore 可以由其它 process 釋放,這時的 semaphore 實際就是個 atomic 的變量,大家可以加或減,因此 semaphore 可以用於進程間同步。
Semaphore 的同步功能是所有系統都支持的,而 Mutex 能否由其他 process 釋放則未定,因此建議 mutex 只用於保護 critical section。而 semaphore 則用於保護某變量,或者同步。
Dead Lock
每一種資源都有一定的 instances,像是可能有 5 個 disk,不止一個的 I/O devices,每一個 process 要利用資源都有以下三種階段:要求資源、使用資源、釋放資源
要死結必須要滿足以下四個條件:
- Mutual exclusion:一個資源一次只能被一個 process 所使用
- Hold and Wait:process 取得一個資源之後等待其他的資源
- No preemption:資源只能由 process 自己釋放,不能由其他方式釋放
- Circular wait:每個 process 都握有另一個 process 請求的資源,導致每一個 process 都在等待另一個 process 釋放資源
System Model 可以用 Resource-Allocation Graph (RAG) 的方式去用圖表描述,如果圖表中沒有 cycle,就不會發生死結,如果有 cycle,則看資源的是不是只有一個 instances,若只有一個,則會發生 deadlock,若不只一個,則有可能發生 deadlock。
我們可以處理 deadlock problem 使用下列三個方式其中之一:
- 使用一個協議 protocol 去預防或是避免 deadlocks,確定系統永遠不會進入死結狀態
- 允許系統進入死結狀態(deadlocked state),然後偵測它,恢復它
- 完全無視這些問題,假裝這些問題從來不曾發生過
deadlock-prevention
提供一組方法去確認至少一個必要的死結情況不會發生。這些方法靠著限制資源的需求來達成預防死結- Mutual exclusion => 對不可共用的資源類型而言,互斥一定成立,而可共用的資源類型,因為可以同時讀取相同檔案,所以一定不會產生。所以無法從這點著手
- Hold and Wait => 必須保證一個 Process 在要求一項資源時,不可以佔用任何其它的資源
- No preemption => 只要某個處理元要不到所要求的資源時,便把它已經擁有的資源釋放,然後再重新要求所要資源
- Circular Wait => 確保循環式等候的條件不成立,我們對所有的資源型式強迫安排一個線性的順序
deadlock-avoidance
要求 OS 給出額外的資訊,關於一個 process 在他的 lifetime 裡會要求的 resource。有了這些額外的資訊,OS 可以決定是否讓 process 的要求繼續等候。為了決定現在的要求是否能滿足,OS 必須考慮現在資源的存量、資源的分量、和未來資源的要求與釋放。
Memory Management Strategies
- 程式 program 必須從 disk 移動到記憶體中,並變成一個 process 才能執行
- CPU 只能直接存取 CPU register 或 memory 的內容
- Memory 中的每個 字元組 word 都有自己的 address,可經由 load/store 對特定 address 作用,在 Memory 和 CPU register 間搬移
- CPU 可以在一個時脈週期 clock 內,存取 register 多次,但是存取相同大小內容的話,若存取 memory 可能要花數個 CPU 時脈週期,因為 memory 速率較 register 慢,造成 CPU需要等待 stall
- 補救方法就是加入存取速率中等的快取記憶體 cache
Base and Limit Registers
兩個 registers 分別記錄該 process 的起始記憶體地址,我們稱為 Base Register,與該 process 所佔記憶體地址大小,我們稱為 Limit Register。Process 會在 CPU 的監督下只能存取範圍內的內容。
Address Binding
User program 在開始執行前,會經過許多步驟
- 原始程式的位址通常只是個符號 (e.g. variable),比如我們知道一個變數一定就需要占著某個記憶體位址
- 在編譯後,該符號化的位址可能重新地位為「程式起始地址後,往後數 000014」
- 鏈結器 (Linker) 或載入器 (Loder) 又會重行定位,把位址 bind 至絕對位址「例如700014」。另外需要注意的是這個絕對位址還是個虛擬位址,user space 基本上從不會知道真正的實體位址
- dynamic load 同時也是一個節省 memory 的方法,program 只有在有需要被用到時才會載入,同時也避免了重複性的載入
Bind 可以在以下步驟完成
- compile time:如果編譯時程式所在的記憶體位置已知,那麼可產生絕對碼 absolute code。如果起始位置變化,必須重新編譯代碼
- load time:如果編譯時不能確定程式所在的記憶體位置,則必須生成 relocatable code
- execution time:如果 process 正要執行時,記憶體區段被移動到另一個區段,則連結時間才會延遲到這個時候(這需要硬體是否支援)
Swap
一方面,在 Memory 中的某些 Process 由於某事件尚未發生而被阻塞運行,但它卻佔用了大量的內存空間,甚至有時可能出現在內存中所有進程都被阻塞而迫使 CPU 停止下來等待的情況;另一方面,卻又有著許多作業在外存上等待,因無內存而不能進入內存運行的情況。顯然這對系統資源是一種嚴重的浪費,且使系統吞吐量下降。
為了解決這一問題,所謂交換是指把內存中暫時不能運行的進程或者暫時不用的程序和數據調出到外存上,以便騰出足夠的內存空間,再把已具備運行條件的進程或進程所需要的程序和數據調入內存。
如果一個 process 的文本,link 這個動作是在 compile 或 load 時完成的,則 swap 回來後也必須在原本的空間,因為相關定址早就已經都決定好了;如果 link 這個動作是在執行到時才做的,則 swap 後可以換到不同位置。
如果一個 process 的文本,link 這個動作是在 compile 或 load 時完成的,則 swap 回來後也必須在原本的空間,因為相關定址早就已經都決定好了;如果 link 這個動作是在執行到時才做的,則 swap 後可以換到不同位置。
Virtual Memory
使應用程式認為它擁有連續的可用的記憶體 (一個連續完整的位址空間),而實際上它通常是被分隔成多個實體記憶體碎片,還有部分暫時儲存在外部磁碟記憶體上在需要時進行資料交換。

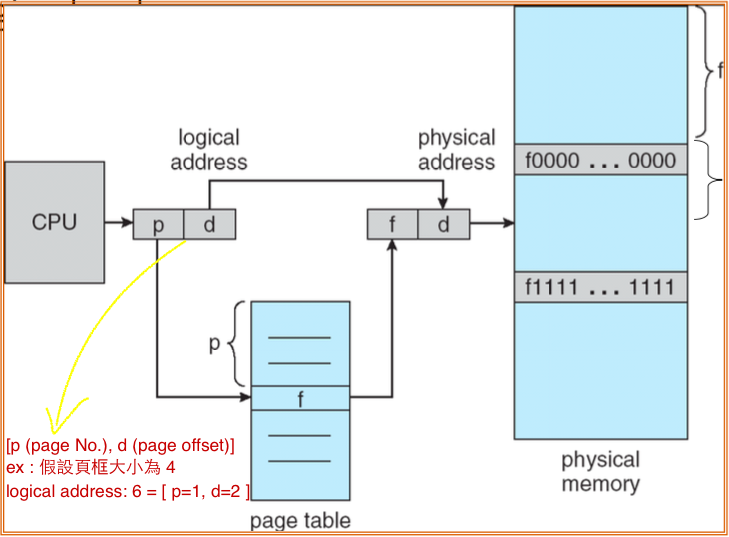
CPU 所產生的是 logical address,RAM 在其 memory-address register 看到的是 physical address,如果這兩者在實務上不相等,那就是所謂 virtual memory 的效果,在兩者之間的 mapping 要透過稱為 memory-management unit (MMU) 的硬體裝置支援來完成。
Physical memory 被分割成 frame 的固定大小區段,logical memory 被分割成 page,disk 中作為 swap 用途的區域也被以相同大小分割。當一個 process 要被執行時,他的 page 就被載入到可用的 frame 中。
外部斷裂 (external fragmentation) 是指記憶體總和剩餘空間雖然足以載入整個行程,但因為剩餘空間被其他行程切割而不連續,所以無法載入行程。
有時行程雖然小於記憶體某段連續的剩餘空間,但在配置給該行程時,仍將整段空間都要走,這種行程額外要求了自己不需要的空間,稱之為內部斷裂(internal fragmentation)。
CPU 所使用的 logical address 由 page number (d) 和 page offset (d) 組成,page number (d) 作為 page table 的 index 找到對應的 physical address 的基底位址 f,f 加上 d 構成實際的 physical address。
運用這種方法,physical memory 就不會有外部斷裂,但還會有內部斷裂,經驗顯示 page 的大小為 4KB 或 8KB 可最小化內部斷裂造成的相關浪費,page 的大小是由 HW 所決定的,一般來說就是 4KB 或 8KB。
Page table 的每一筆通常是 4 bytes (32 bits),(此長度是可變的),32 bit 就可指向 2^32 個 physical address 欄位,若每一個 page 是 4KB,那代表 physical address 大小為 2^44 bytes (16TB)。現代作業系統 32bit/64bit 即代表 logical address 的位址空間,依據上述算法,即代表支援至多 16TB 的 RAM。
當然實際上 logical address space 應該要維持是 physical address space 的數倍,因為不同 logical address 常常可以對應到同一個 physical address。 logical address 對於 VM 也有直接的幫助。
Page table 是由 OS 所控制的,user process 看到的 address 永遠都只是 logical address。由於 OS 要管理 mapping 的 page table,所以需要知道哪些 physical address 中的 frame 還可以用,於是另外有一個 frame table 在記錄此資訊。(Page table 是 OS 和 MMU 共同維護)
運用這種方法,physical memory 就不會有外部斷裂,但還會有內部斷裂,經驗顯示 page 的大小為 4KB 或 8KB 可最小化內部斷裂造成的相關浪費,page 的大小是由 HW 所決定的,一般來說就是 4KB 或 8KB。
Page table 的每一筆通常是 4 bytes (32 bits),(此長度是可變的),32 bit 就可指向 2^32 個 physical address 欄位,若每一個 page 是 4KB,那代表 physical address 大小為 2^44 bytes (16TB)。現代作業系統 32bit/64bit 即代表 logical address 的位址空間,依據上述算法,即代表支援至多 16TB 的 RAM。
當然實際上 logical address space 應該要維持是 physical address space 的數倍,因為不同 logical address 常常可以對應到同一個 physical address。 logical address 對於 VM 也有直接的幫助。
Page table 是由 OS 所控制的,user process 看到的 address 永遠都只是 logical address。由於 OS 要管理 mapping 的 page table,所以需要知道哪些 physical address 中的 frame 還可以用,於是另外有一個 frame table 在記錄此資訊。(Page table 是 OS 和 MMU 共同維護)
共用分頁
Page table 帶來的另一個好處就是可以支援共用分頁,每一個 process 都有自己的 page table,若某一 page 為 pure code 文本,則他在 physical address 中只需要存在一份,各 process 在該 page 都對應到同一個 physical address 的 frame。一些作業系統對於 IPC 的 shared memory 也是透過共用分頁來實作的。
Dynamic link/load
Program 需要先經過 link 找到文本以及 load 到記憶體中以明確 address 才得以執行。dynamic link 一般用在系統語言 library,比如 stdlib,因為他們非常常被其他 program 所使用,若在每一個 user program 都放一份太過浪費。編譯階段會在該段做個記號,該記號其實就是一小段 code 指示該如何去找到該 program,當執行到該記號時,首先則會檢查該 program 文本是否已經在 memory 中,若沒有則將其找到並載入,並執行,與此同時 link 也完成,之後不用在 link 一次。
更進一步來說,可以在平台上維持不同版本的 library,user program 可指定其要 link 的版本,所以又稱為 shared libraries。
Dynamic link 需要 OS 的支持,因為要做到某一 shared library 不被重複的載入 memory,也就是後來者需要去 access 先來者的 address space 中載入的 shared library 的部分,這想必需要 OS 介入才能進行。而 dynamic load 則不需要 OS 的介入,純粹是在 coding 時的一種技巧選擇,以及須將 library 編譯成 relocatable code。Dynamic link 明確意涵 share 的方式來達到 save memory 的效果,藉由 OS 的幫助;dynamic load 是透過需要時才載入,不需要時釋放來達到 save memory 的效果,須由程式設計師明確使用。
swap
在導入 virtual memory 後,swap 機制即變成這樣:
- 檢查 PCB,確認此 address access 是否合法
- 如果非法,代表這是一個傳統典型 page fault,終止程式;如果合法,那代表此 page fault 是由 lazy swap 機制導致
- 在 physical memory 中找到空白的 frame,這是透過檢查 frame table 達成
- 產生一個 disk io request 將該 page 從 disk (或者是一個更快的用於 swap 用途的 secondary storage) 載入 physical memory 的選定 frame
- 修改 page table 讓該 page map 到該 physical memory 的 frame
- 重新執行 report page fault 的那個指令
Process 在開始時會做 demand paging,而 lazy swap 所造成的成本是與 page fault 發生的機率相關的。如果 page fault 越常發生,平均 demand paging 時間就會越長。
copy-on-write
比如 fork() 產生的子行程,其內容在很多部分都是複製自父行程,所以在這個時間點可以以共用 page 的方式處理,直到子行程有需要去改變到某 page 涵蓋到的內容,才實際做複製的動作。Linux 另外提供了 vfork() 方法,就是應用於預期子行程和父行程完全共用分頁的狀況。實際運作上相當於, vfork() 之後父行程就暫停,子行程使用了父行程的 address space,子行程接束之後,父行程所復得的 address space 都是子行程操作過的狀態。
page replacement
- FIFO
- optimal page-replacement alogrithm
- LRU
另外當 swap 要發生時,可以使用 dirty bit 來增進效率,此 bit 用於知道那個要從 memory 中被犧牲置換到 disk 的 page 是否真的需要被寫回 disk,如果他根本沒被改過,那就不會要花一次費時的 disk io。
memory mapping
map disk 中的 file 到 memory
- 對於 file 的初次 access 會產生一個 demand paging 並造成 page fault
- 一個 page size 大小的檔案部分內容被載入 memory
- 此後在這個 page 範圍內的檔案讀取都不用實際透過 read() / write()
- 系統會周期性檢查某 page 需不需要被寫回 disk,Linux 上 user 可透過 "sync" 要求立即寫回。另外做 close file 時也會有檢查
memory mapping I/O
保留某 memory address space map 到 device 的 register。如此便不用明確透過 CPU 和 device controller 在 RAM, CPU register, device register 間搬移 data;只需要對 control register 做操作以溝通在 memory 區段中的 data 是否 ready。
File System
技術上來說,檔案系統是一種儲存和組織電腦檔案和資料的方法,它使得對其存取和尋找變得容易。檔案系統通常使用硬碟和光碟這樣的儲存裝置,並維護檔案在裝置中的實體位置。但是,檔案系統也可能僅僅是一種存取資料的介面而已,實際的資料是透過網路協定(如 NFS、SMB、9P 等)提供或於內部記憶體上,甚至可能根本不存在對應的檔案(如 proc)。嚴格地說,檔案系統是一套實作了資料的儲存、分級組織、存取和獲取等操作的抽象資料型式(Abstract data type),為了適切地定義檔案,必須考慮檔案上所表現的操作如下:
- 建立檔案:建立檔案需要兩個步驟。首先,為了這個檔案,其空間必須在檔案系統中被找到。其次,必須在目錄中為新檔案做一個項目。
- 寫入檔案:需要做一次系統呼叫,指定檔案名稱和欲寫入檔案之資訊。系統必須保持一個寫入指標到檔案的位置,下一個寫入在這個位置發生。當寫入發生時,寫入指標必須被更新。
- 讀取檔案:一個系統呼叫指定了檔案的名稱和檔案下個區段被放置的處所(在記憶體中包括目錄、區段)。一旦那個區段被讀出,此指標即被更新。
- 重置擋案:搜尋目錄以找到相關的進入點,然後把目前檔案位置設定成某一固定值。這個檔案操作也稱為檔案搜尋。
- 刪除檔案:搜尋目錄以找此檔案。在找到相關的目錄項目後,釋放所有檔案的空間,並且將此目錄項目作廢。
- 縮減擋案:使用者可以使用此功能使檔案特性保持不變(除了檔案長度),但檔案恢復為長度零。
而對於每一個開啟的檔案也都有以下相關的資訊:
- 檔案指標:對於 read 和 write 系統呼叫沒有包含檔案位移的系統而言,它們必須追蹤上一次讀/寫的位置,以做為目前檔案位置的指標。
- 檔案開啟計數:檔案開啟計數器記錄開啟和關閉的次數,在最後一個關閉動作時就變成零。然後系統就可以把該檔的進入點從表格移去。
- 檔案的磁碟位置:檔案在磁碟位置的資料存放在記憶體中,以避免每一次檔案操作時都必須從磁碟讀出。
- 存取權限:行程以一種存取模式開啟檔案,這個資訊被存放在行程表中,所以作業系統可允許或拒絕輸入/輸出的需求。
一個 disk 可以被分隔成多個 partition,每個 partition 可以建立自己的 file system。而一個 partition 也可以跨越 disk,如 RAID 應用。Partition 是軟體層 file system 所需的邏輯概念,file system 的一大目的就是是抽象化了檔案的存取,由其底層去和 disk driver 對接,而 kernel 在欲對檔案做存取時就可以 high level 的一致性的邏輯對異質的外部存儲裝置。
 不同的檔案系統型態有不同特性,比如 tmpfs 一般是會給易揮發性的記憶體中間立的檔案系統,系統重啟內容就會消失。安裝檔案系統即稱為 mount
不同的檔案系統型態有不同特性,比如 tmpfs 一般是會給易揮發性的記憶體中間立的檔案系統,系統重啟內容就會消失。安裝檔案系統即稱為 mount







I/O Systems
電腦系統與裝置的通訊,借由所謂的連接阜,並使用相同的纜線,這叫做匯流排 Bus。爲了節省硬體代價,高速彙流排連接高速傳輸裝置,慢速彙流排連接慢速傳輸裝置

CPU HW 有一個 interrupt-request pipe,CPU 在每執行一個指令之後會檢查這個 bus,如果其中有中斷要處理,就在儲存狀態後跳去對應的中斷處理常式。一般 CPU 有兩個 pipe,一個是 maskable 一個 non-maskable,maskable 指的是 CPU 可以在執行不可被中斷的一連串指令時,不理會 maskable 的部分。device controller 一般都是放置 maskable pipe。
控制器 Controller
控制器概念:可操控連接阜、匯流排、或裝置的電子零件組合。
控制器內置 register,用于存儲資料與控制訊號,方便 CPU 透過 register 讀取資料或命令。某些 device 擁有自己的內建 controller。
控制器與處理器的通訊:
- 使用特殊 I/O 指令來傳輸要送往某 I/O 連接阜位址的位元或字元,I/O 指令驅動匯流排線選擇適當的裝置,再將位元輸入或寫出到 device register
- device driver load data 到 device controller 的 register (注意 device driver 是在 OS kernel 中,相對 device controller 而言,device controller 是在外部而 device driver 是在內部)
- device controller 檢查其 register 內容以決定要做什麼動作
- device controller 將需要的 data 在其 local buffer 和 device 間轉移
- 轉移完成後 device controller 發出中斷給 driver
- driver 將控制權還給 OS,若有需要也告知其 device controller 的 local buffer 所在位址
- 使 device controller 支援記憶體映對 I/O,也就是 Direct Memory Access (DMA)
- 上述第 5 步,CPU 若要使用 device controller 的 local buffer 中的 data,須自己在 buffer 和 Memory 間搬移
- DMA 就是讓 device controller 可以直接負責 data 在 local buffer 和 Memory 間的搬移,不需 CPU 的介入
- 也就是基本取決於 DMA 可用區域的大小而決定了中斷的次數,一定小於要求 CPU 在 local buffer 和 Memory 間的搬移,每一個 word 就要一次中斷
- 以上兩種方式一起使用
留言
張貼留言